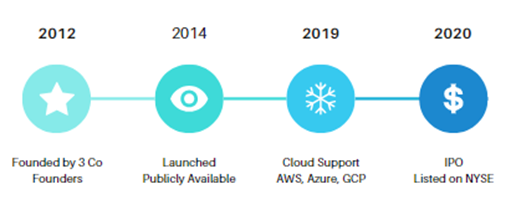
December 20, 2023 asghars
- Snowflake is a self-managed data platform or data cloud
- Snowflake makes storing, processing, and analyzing data faster and more flexible compared to traditional options
- Snowflake uses a brand-new SQL query engine designed specifically for the cloud
- From self-managed means:
- You don't need to install, configure, or manage any physical or virtual hardware or software
- Snowflake takes care of ongoing maintenance, upgrades, and tuning for you